
That is half 2 of a collection on algorithm benchmarking and choice on x86_64 and AArch64 methods. You could find half 1 right here. Within the earlier publish we went by means of the algorithms we’re to benchmark and broke a few of their workings down, offering predictions alongside the way in which as to how they’d stack up. Now it is time to put them to the check and see which comes out on high.
You could have seen there was a niche within the numbering of the algorithms, between vol2.c and vol4.c. vol3.c is a dummy program offered to us with out the quantity scaling algorithm, so we will isolate the efficiency of that one operate. Alternatively, we will accomplish that with code by together with the C time library and timing the scaling operate. This technique is much less error susceptible so I will be benchmarking the algorithms on this method.
Step one is to extend the pattern dimension in our header to work with a considerable sufficient dataset in our benchmarking to get some significant outcomes. I cranked up the pattern quantity to 1600000000, after which I set to work inserting the timing code into every of the applications.
For instance vol0.c seems like so:
// ---- That is the half we're curious about!
// ---- Scale the samples from in[], putting ends in out[]
clock_t t;
t = clock();
for (x = 0; x < SAMPLES; x++) {
out[x]=scale_sample(in[x], VOLUME);
}
t = clock() - t;
printf("Time elapsed: %fn", ((double)t)/CLOCKS_PER_SEC);
I then ran it in a loop to execute 20 occasions and ship the output to a log file like so:
for ((i = 0; i < 20; i++)) ; do ./vol0 ; carried out |&tee vol0output.log
After following these steps for all of the applications I had my outcomes for the AArch64 system prepared to check. I did the identical for the x86_64 algorithms, omitting the final two algorithms that use SIMD as they will not run on that structure. The outcomes are as follows:
AArch64 Outcomes
| Algorithm | Vol0.c | Vol1.c | Vol2.c | Vol4.c | Vol5.c |
|---|---|---|---|---|---|
| Time (s) | 5.286 | 4.644 | 11.257 | 2.756 | 2.837 |
| 5.251 | 4.587 | 11.258 | 2.776 | 2.777 | |
| 5.295 | 4.623 | 11.226 | 2.766 | 2.803 | |
| 5.277 | 4.573 | 11.239 | 2.784 | 2.784 | |
| 5.287 | 4.603 | 11.25 | 2.757 | 2.801 | |
| 5.283 | 4.568 | 11.229 | 2.796 | 2.787 | |
| 5.283 | 4.581 | 11.234 | 2.74 | 2.8 | |
| 5.311 | 4.566 | 11.244 | 2.782 | 2.806 | |
| 5.287 | 4.601 | 11.233 | 2.848 | 2.796 | |
| 5.244 | 4.639 | 11.244 | 2.756 | 2.755 | |
| 5.279 | 4.558 | 11.239 | 2.744 | 2.763 | |
| 5.293 | 4.56 | 11.236 | 2.782 | 2.79 | |
| 5.288 | 4.632 | 11.233 | 2.73 | 2.886 | |
| 5.27 | 4.591 | 11.262 | 2.775 | 2.818 | |
| 5.277 | 4.567 | 11.243 | 2.721 | 2.836 | |
| 5.31 | 4.576 | 11.234 | 2.812 | 2.799 | |
| 5.295 | 4.552 | 11.237 | 2.784 | 2.789 | |
| 5.25 | 4.567 | 11.23 | 2.776 | 2.806 | |
| 5.283 | 4.565 | 11.235 | 2.798 | 2.762 | |
| 5.248 | 4.564 | 11.215 | 2.823 | 2.824 | |
| Common | 5.279 | 4.585 | 11.238 | 2.775 | 2.800 |

It seems like these outcomes kind of verify what we predicted, with the quickest 2 being people who took benefit of SIMD optimization to run concurrently. Vol2.c was method behind in execution time at a whopping common of 11.238 seconds per execution, over double the subsequent slowest algorithm. This confirms that precalculating a desk of outcomes may be extremely expensive in compute time as a result of cache not being quick sufficient to outpace the mathematics unit of the processor. The naïve method in Vol0.c of multiplying every pattern by a scale issue with a number of kind conversions within the course of considerably unsurprisingly takes the second slowest tempo. Avoiding the conversions by bit shifting in Vol1.c yields a barely sooner runtime. Now onto the x86_64 outcomes:
x86_64 Outcomes
| Algorithm | Vol0.c | Vol1.c | Vol2.c |
|---|---|---|---|
| Time (s) | 2.91 | 2.755 | 3.574 |
| 2.849 | 2.762 | 3.552 | |
| 2.764 | 2.747 | 3.543 | |
| 2.753 | 2.739 | 3.502 | |
| 2.763 | 2.771 | 3.497 | |
| 2.761 | 2.739 | 3.503 | |
| 2.77 | 2.774 | 3.527 | |
| 2.77 | 2.77 | 3.507 | |
| 2.782 | 2.751 | 3.5 | |
| 2.752 | 2.763 | 3.496 | |
| 2.765 | 2.757 | 3.53 | |
| 2.753 | 2.757 | 3.501 | |
| 2.776 | 2.759 | 3.515 | |
| 2.771 | 2.758 | 3.527 | |
| 2.768 | 2.761 | 3.5 | |
| 2.758 | 2.777 | 3.518 | |
| 2.783 | 2.749 | 3.499 | |
| 2.764 | 2.747 | 3.496 | |
| 2.772 | 2.752 | 3.504 | |
| 2.777 | 2.756 | 3.502 | |
| Common | 2.778 | 2.757 | 3.514 |
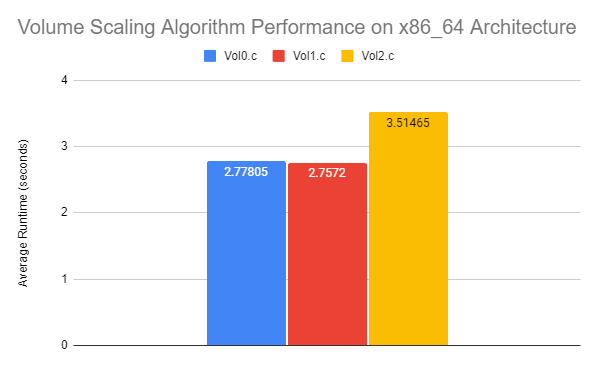
The execution occasions on x86_64 inform the same story, though there are a number of fascinating distinctions. First, the kind conversions that set Vol0.c again a lot within the AArch64 benchmarks appear to have a lot much less of an impression right here. Vol0.c and Vol1.c share nearly precisely the identical runtime, though working with one kind and bit shifting did shave off a number of milliseconds. Additionally of word is that Vol2.c does not appear to incur the huge efficiency penalty seen on its AArch64 counterpart. That is proof that the cache on this machine’s processor is way nearer to the mathematics unit when it comes to getting the outcomes we’d like.
In conclusion, this was a watch opening expertise that confirmed my information about some great benefits of SIMD whereas giving particular proof to assist simply how briskly it’s in comparison with conventional processing. We additionally realized simply how essential it’s to know the machine you are optimizing for intimately, to account for variations like that between the algorithm utilizing the precalculated desk on the AArch64 machine vs the x86_64 one. Doing so can inform your programming choices and assist keep away from making expensive assumptions that on this case would possibly imply greater than doubling your runtime.