
One of many objectives of a customer data platform is to make the motion of knowledge from any supply to any vacation spot straightforward whereas guaranteeing correctness, reliability, effectivity, and observability. In that sense, reverse ETL isn’t any totally different, it is just another data pipeline.
In 2019, RudderStack began as an information infrastructure device supporting event streaming to a number of locations, together with the information warehouse. From the outset, we made the information warehouse (or information lake/lakehouse 🙂) a first-class citizen, supplying automated pipelines that enable firms to centralize all of their buyer information within the warehouse. It is necessary to not overlook the influence of this resolution, as a result of putting the storage layer on the heart and making all the information accessible is vital to unlocking a plethora of use circumstances. However getting the information into the warehouse is mainly solely helpful for analytics. It is getting it again out that allows model new use circumstances, and that is the place Reverse ETL is available in.
What’s Reverse ETL?
Reverse ETL is a brand new class enabling the automation of name new enterprise use circumstances on high of warehouse information by routing mentioned information to cloud SaaS options, or operational programs, the place gross sales, advertising and marketing, and buyer success groups can activate it.
Constructing pipelines for Reverse ETL comes with a singular set of technical challenges, and that’s what this weblog is about. I will element our engineering journey, how we constructed RudderStack Reverse ETL, and the way Rudderstack Core helped us clear up greater than half of the challenges we confronted. In a approach, constructing this felt like a pure development for us to deliver the fashionable information stack full circle.
What’s RudderStack Core?
RudderStack Core is the engine that ingests, processes, and delivers information to downstream locations. Most important options:
- Ingest occasions at scale
- Deal with again strain when locations are usually not reachable
- Run person outlined JavaScript features to switch occasions on the fly
- Producing studies on deliveries and failures
- Ensures the ordering of occasions delivered is identical because the order wherein they’re ingested
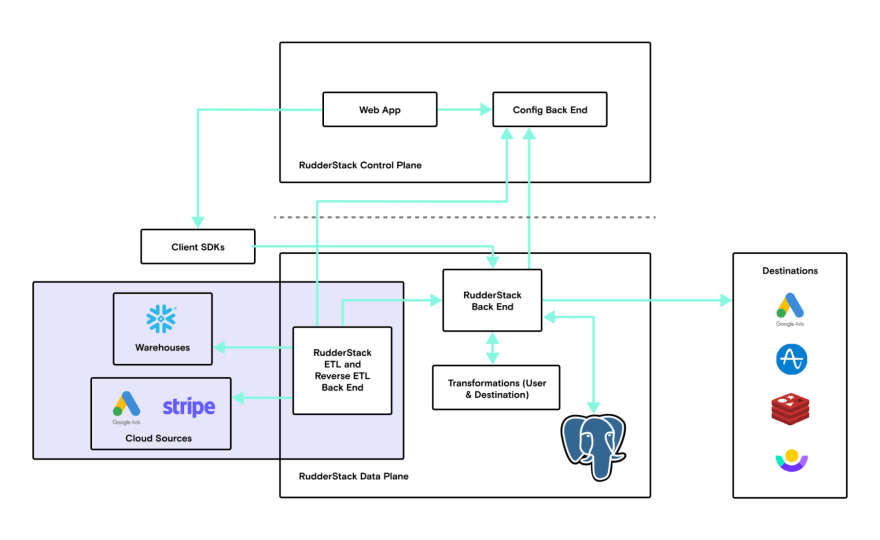
The technical challenges we confronted constructing Reverse ETL
First, I will give an eagle eye view of the totally different phases to constructing Reverse ETL and the challenges related to them. Alongside this stroll, I will clarify how RudderStack Core helped us launch it incrementally, making a number of large hurdles a chunk of cake. I need to give main kudos to our founding engineers who constructed this core in a “suppose large” approach. Their foresight drastically diminished the quantity of effort we needed to put into designing and constructing engineering options for Reverse ETL.
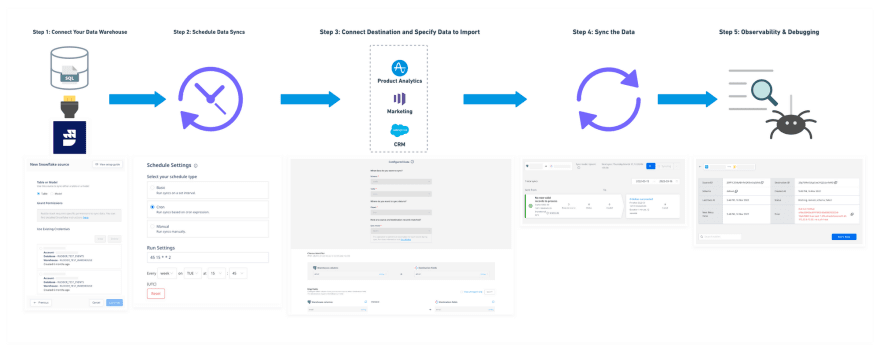
1. Making a Reverse ETL pipeline
Out of all of the steps, this was the simplest one, although it was nonetheless a bit difficult.
1.1 Making a supply
Warehouse supply creation will get difficult due to credentials and due to the learn and write permissions one wants to take care of transient tables for snapshots and evaluating diffs. It is necessary to make sure the person can simply present solely the required permissions for reverse ETL, so the pipeline device doesn’t find yourself with entry to extra tables within the buyer’s manufacturing than wanted or with any pointless write entry.
This can be a difficult downside made more durable by the variations between warehouses. We requested ourselves a number of key questions when constructing this:
- How can we simplify and streamline the instructions and accesses for various warehouses?
- How can we assist one validate these credentials when making a supply?
On this occasion, our management airplane enabled us to reuse and construct on present elements. This was essential as a result of we wished to make validations in a generic approach, so they might be reusable as we proceed including extra information warehouse and information lake sources. Our group iterated loads on how one can educate customers on which permissions are required and why. Try our documentation on creating a new role and user in Snowflake for an instance. We needed to work to make sure solely related validations and errors would present when organising a supply, and we got here up with sooner methods to run some validations.
For instance, in our first iteration we used Snowflake queries to confirm whether or not the offered credential allowed us to validate the wanted schema for RudderStack, so we may learn, write, and handle transient tables to it. These queries had been scheduled within the regular queue method by Snowflake, however for some clients it took minutes for these queries to run. So, we discovered a better resolution from Snowflake the place SHOW instructions don’t require a operating warehouse to execute. With this new resolution, validations full inside a minute or much less for all clients. As we constructed out the reverse ETL supply creation stream, the large wins that we adopted from the prevailing RudderStack Core platform had been:
- Our WebApp React elements’ modular designs had been re-usable within the UI
- We had been capable of re-use code for managing credentials securely and propagate it to the Reverse ETL system within the information airplane
- We had been capable of ship sooner as a result of RudderStack Core allowed us to give attention to the person expertise and options vs. constructing infrastructure from the bottom up
1.2 Making a vacation spot
Each information pipeline wants a supply and a vacation spot. When it got here to creating locations for Reverse ETL, RudderStack Core actually shined. Enabling present vacation spot integrations from our Occasion Stream pipelines was easy. We constructed a easy JSON Mapper for translating desk rows into payloads and had been capable of launch our Reverse ETL pipeline with over 100 locations out of the field. At present the depend is over 150 and rising! We’re additionally incrementally including these locations to our Visual Data Mapper. For additional studying, here’s a blog on how we backfilled information into an analytics device with Reverse ETL and a few Person Transformations magic.
2. Managing orchestration
The Orchestrator was essential and one of many more difficult programs to construct, particularly on the scale RudderStack is operating. Reverse ETL works like several batch framework just like ETL. In case you’re acquainted with instruments like Apache Airflow, Prefect, Dagster, or Temporal, you understand what I am speaking about—the means to schedule advanced jobs throughout totally different servers or nodes utilizing DAGs as a basis.
In fact, you are most likely questioning which framework we used to construct out this orchestration layer. We did discover these choices, however in the end determined to construct our personal orchestrator from scratch for a number of key causes:
- We wished an answer that may be simply deployed together with a rudder-server occasion, in the identical sense that rudder-server is definitely deployed by open supply clients.
- We wished an orchestrator that might doubtlessly rely on the identical Postgres of a rudder-server occasion for minimal set up and could be straightforward to deploy as a standalone service or as separate staff.
- We love Go! And we had enjoyable tackling the problem of constructing an orchestrator that fits us. In the long term, this can allow us to switch and iterate based mostly on necessities.
- Constructing our personal orchestrator makes native improvement, debuggability and testing a lot simpler than utilizing advanced instruments like Airflow.
- We love open supply and wish to contribute a simplified model of RudderStack Orchestrator sooner or later.
3. Managing snapshots and diffing
Let’s think about one easy mode of syncing information: upsert. This implies operating solely updates or new inserts in each scheduled sync. There are two methods to do that:
- Marker column: On this methodology, you outline a marker column like updated_at and use this in a question to search out updates/inserts for the reason that earlier sync ran. There are a number of points with this method. First, you must educate the person to construct that column into each desk. Second, many instances it is tough to take care of these marker columns in warehouses (for software databases, that is pure, and lots of instances DBs present this with none additional developer work).
- Main key and diffing: On this methodology, you outline a major key column and have advanced logic for diffing.
We went with the second possibility. One main purpose was that we may run the answer on high of the shopper’s warehouse to keep away from introducing one other storage element into the system. Additionally, the compute energy and quick question help in trendy warehouses had been excellent for fixing this with queries and sustaining snapshots and diffs to create transient sync tables.
Hubspot desk after incremental sync of recent rows:

Sync display in RudderStack:
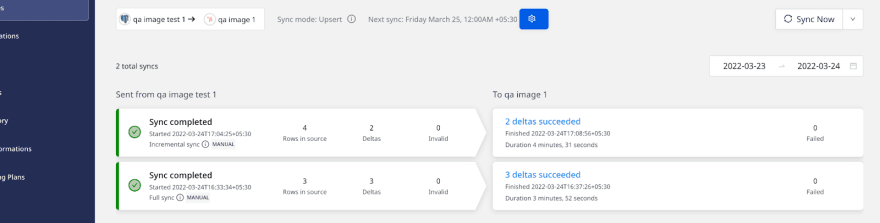
Snapshot desk view:

Now, you is perhaps pondering: “What is the large deal? It is simply creating some queries, operating them and syncing information?” I want, however it’s not so simple as it appears to be like. Additionally, this was one of many challenges RudderStack core could not assist with. Listed here are a number of of the challenges that emerge whenever you dig deeper into the issue:
- Diffing must be very extensible, not just for the a number of warehouse sources we already help, but in addition for integrating with future warehouse and information lake sources.
- It’s important to implement state machine based mostly duties to deal with software program or system crashes and any errors that happen throughout a mess of dependencies.
- It’s important to keep report ordering checkpoints throughout sync to make sure a better assure of delivering precisely as soon as to locations.
- It’s important to help performance for pausing and resuming syncs.
- It’s important to deal with supply of information that didn’t ship on the earlier sync.
On high of these issues, there have been various different attention-grabbing issues we discovered associated to reminiscence, selection of CTE vs momentary desk, columns information varieties, structs in BigQuery, and extra, however that is one other publish for one more day.
4. Managing syncing, transformations, and supply to locations
RudderStack Core considerably shortened the event cycle for syncing, operating transformations within the information pipeline, and closing supply to locations.
Largely, it is because our Reverse ETL and Occasion Stream pipelines have loads in frequent relative to those use circumstances. In actual fact, from a supply perspective, Reverse ETL pulling from warehouse tables is far less complicated than SDK sources, so we had been capable of have extra exact management over ingestion and leverage rudder-server for all the pieces else. This is what rudder-server took care of:
- Vacation spot transformations (mapping payloads to vacation spot API specs)
- Calling the proper APIs for add, replace, delete, and batch APIs if supported
- Person transformations (customized JavaScript code written by customers to switch payloads)
- Managing the speed limits of vacation spot APIs (which fluctuate considerably) and offering a again strain mechanism for Reverse ETL
- Dealing with failed occasions with retries and offering lastly failed occasions again to Reverse ETL
- A mechanism to determine completion of sync duties
- New integrations and have enhancements (routinely usable by our Reverse ETL pipeline when deployed to RudderStack Core)
Although the objects above had been enormous wins from RudderStack Core, there have been another attention-grabbing issues we needed to clear up as a result of we use rudder-server as our engine to ship occasions. I will not dive into these now, however here is a pattern:
- It is difficult to ship occasions to our multi-node rudder-server in a multi-tenant setup
- It is difficult to ensure occasion ordering for locations that require it
- Now we have to respect the speed limits of various locations and use again strain mechanisms, so we do not overwhelm rudder-server, all whereas sustaining quick sync instances
- Acknowledging completion of a sync run with profitable supply of all information to vacation spot
5. Sustaining pipelines with observability, debuggability, and alerting
Any automated information pipeline wants some stage of observability, debugging, and alerting, in order that information engineers can take motion when there are issues and align with enterprise customers who’re depending on the information.
That is significantly difficult with programs like Reverse ETL. Listed here are the principle challenges we needed to clear up:
- Lengthy operating processes should account for software program crashes, deployments, upgrades, and useful resource throttling
- The system has dependencies on a whole bunch of locations, and people locations have API upgrades, downtime, configuration adjustments, and many others.
- As a result of RudderStack would not retailer information, now we have to create modern methods to perform issues like observability by way of issues like dwell debuggers, in-process counts (like sending/succeeded/failures), and reasoning for any errors which are essential
Accounting for software program crashes, deployments, upgrades, and useful resource throttling required a considerate design for Reverse ETL, here is how we did it:
- State machine: State based mostly programs look easy however are extremely highly effective if designed properly. Particularly, if an software crashes, it may well resume accurately. Even failed states like failed snapshots might be dealt with correctly by, say, ignoring it for the subsequent snapshot run.
- Granular checkpoint: This helps ensure no duplicate occasions shall be despatched to locations. For instance, say we ship occasions in a batch of 500 after which checkpoint. The one chance could be that one total batch may get despatched once more if the system restarted or if it occurred throughout deployment because it was despatched to rudder-server, however couldn’t checkpoint. On high of this, rudder-server solely has to take care of a minimal batch of knowledge so as to add dedupe logic on high as a result of it would not want to save lots of an identifier for all information for a full sync activity.
- Help for dealing with shutdown and resuming: Sleek shutdown dealing with is essential for any software, particularly for lengthy operating stateful duties. My colleague Leo wrote an amazing blog post about how we designed graceful shutdown in Go, which it is best to positively learn.
- Auto scale programs: Robotically scaling programs deal with duties which are operating in a distributed system, which is important for dealing with scale, each for Reverse ETL aspect in addition to the buyer (rudder-server). At any given time a Reverse ETL activity is perhaps operating on a single node, however might need to be picked up by one other node if the unique node crashes for some purpose. On the buyer aspect (rudder-server), information factors is perhaps despatched to shoppers operating on a number of nodes. Guaranteeing lesser duplicates, in-progress efficiently despatched information, and acknowledging completion of sync duties are actually attention-grabbing issues at scale.
- Correct metrics and alerts: We added intensive metrics and varied alerts, like time taken for every activity, variety of information processing from extraction to transformation to vacation spot API calls, sync latencies for batches of information, and extra.
- Central reporting on high of metrics: Past simply metrics for Reverse ETL, there’s a want for a central reporting system as a number of programs are concerned in operating the pipeline, from extraction to closing vacation spot. We wished to seize particulars for all phases to make sure we had full auditability for each pipeline run.
Once more, RudderStack Core was an enormous assist in delivery a number of of the above elements of the system:
- Destinations: relating to integrations, upkeep is essential as a result of issues have to be stored updated. Many instances issues fail due to vacation spot API upgrades or totally different charge limits, to not point out repairs like including extra help for brand spanking new API variations, batch APIs, and many others. As a result of locations are part of RudderStack Core, the Reverse ETL group would not have to take care of any vacation spot performance.
- Metrics: rudder-server already included metrics for issues like efficiently despatched counts, failed counts with errors, and extra, all of which we had been ready to make use of for our Reverse ETL pipelines.
- Live Debugger: Seeing occasions stream dwell is extremely helpful for debugging whereas sync is operating, particularly as a result of we do not retailer information in RudderStack. We had been ready to make use of the prevailing Reside Debugger infrastructure for Reverse ETL.
Concluding ideas
Constructing out our Reverse ETL product was a tremendous expertise. Whereas there have been many enjoyable challenges to resolve, I’ve to reiterate my appreciation for the foresight of our founding engineers. As you possibly can see, with out RudderStack Core this might have been a way more difficult and time consuming undertaking.
In case you made it this far, thanks for studying, and if you happen to love fixing issues like those I lined right here, come be a part of our group! Try our open positions here.