
1. Intro
Opposite to its commonly-praised simplicity, Solidity isn’t any joke. Don’t be deceived by its outward resemblance with general-purpose programming languages: Solidity and Ethereum run-time surroundings itself are fraught with many ‘traps and pitfalls’, which, being stumbled upon, can enormously improve the time for debugging.
Listed here are simply a number of the tough peculiarities:
- There are a number of several types of reminiscence obtainable to the contract;
- Turing incompleteness (though there are nearly no restrictions in comparison with Bitcoin)
- The essential information sort is a 256-bit integer (32 bytes);
- The byte order is big-endian, not like in x86, the place it’s little-endian;
- The solidity compiler might generate an error with out specifying a line or a supply file which it couldn’t compile;
- Some seemingly innocuous and concise language constructs can unfold into numerous inefficient bytecode.
On this publish we delve deeper into the latter intricacy and can pin down what precisely the compiler turns solidity code into. For such functions, disassemblers and decompilers are generally used.
Utilizing a disassembler by itself isn’t trivial. You’ll want to be effectively versed within the directions of the Ethereum virtual machine, keep in mind an insane quantity of details and precedents, mentally carry out stack operations, and perceive the nuances of Ethereum inside workings. Trying to find compilation outcomes for code sections of curiosity within the assembler instructions itemizing is a protracted and exhausting activity. Right here the decompiler can definitely turn out to be useful.
Decompilers settle for byte-code as an enter and restore the high-level code in accordance with a particular set of heuristics. With such code at hand it’s simpler to check blocks of supply code with assembler directions. The decompiler requires solely bytecode to work, if any. It may well additionally retrieve the bytecode by itself, if the working community and the contract tackle are specified.
Nonetheless, the output code of the decompiler could be very completely different from the unique one. There are a number of causes for that. To begin with, there aren’t but any well-developed decompilers for Solidity, which means that that you must be prepared for all kinds of bugs and glitches. Furthermore, as source-code variable names are sometimes misplaced throughout compiling, the decompiler is compelled to substitute them with its personal, devoid of any which means (a, b, c, d, … or var1, var2, var3, …). Such dissimilarities result in the necessity for one more time-consuming supply code mapping and handbook collation.
Thus, it takes lots of effort and time to determine what a number of drawback strains of code on solidity flip into. Nonetheless, there’s a higher approach.
The preferred framework for working with Solidity code is Truffle. When compiling, along with the bytecode of the contract, it generates loads of different helpful information. And it’s this data which is able to assist us in our endeavours!
Utilizing this information we will kind a comparability of the supply code and the directions in two handy views without delay: both matching a source-code to the directions or the opposite approach round. Now, let’s have a look at a simplified illustration of “instruction — code fragment”.
2. Mapping directions with code fragments
After a profitable contract compilation, Truffle writes a set of json-files to the construct/contracts subdirectory of the challenge. Every of those recordsdata corresponds to a source-code file in Solidity and accommodates the next data:
- Contract bytecode;
- Abi (the knowledge required to name the strategies of the contract and consult with its fields);
- Contract supply code;
- Supply map;
- Summary syntax tree;
- Contract tackle after deploying to the community.
For our functions, we’ll think about Contract supply code, Contract bytecode and Supply map. Whereas the primary one is kind of apparent, the opposite two have to be mentioned in additional element. Let’s begin by trying on the Supply map.
2.1. Supply Map
The aim of the Supply map is to match every contract instruction to the part of the supply code from which it was generated. To make the matching potential, the tackle of the supply code fragment is saved within the supply map for each instruction. Easy compression is used to avoid wasting cupboard space: sure tackle fields are omitted if they’re the identical as within the earlier instruction.
Now let us take a look at the Supply map format. The delimiters are semicolon and colon: the previous is used between the supply map parts, and the latter — between the fields within the aspect. The sector consists of three primary parts figuring out the tackle of the corresponding fragment of the supply code (so as of succession: offset from the start of the file, fragment size, file identifier). The fourth aspect is the kind of leap instruction, however it isn’t vital for supply mapping.

The determine above reveals the start of the supply map, which accommodates data for five directions. Whereas the instr1 aspect accommodates all fields, the instr2 and instr3 are empty, which implies that the tackle of the supply code fragment for the second and the third directions within the contract bytecode is similar as for instr1. Within the instr4 solely the primary two fields are set, indicating that solely the offset and size have modified, with the file ID and the kind of transition instruction unchanged. Within the instr5 there are three fields, so solely the kind of transition instruction stays the identical as in instr1. A price of -1 within the file ID subject signifies that the instruction doesn’t match any of the consumer supply recordsdata.
To kind by way of the code parsing, first let’s break down the Supply map into parts:
const gadgets = sourceMap.break up(‘;’);
Now undergo them, storing present subject values within the accumulator in case the next parts will lack the information in a number of fields. Although, at first look, it looks as if the Array.prototype.scale back() perform could be of use, there are higher choices. It’s inconvenient to make use of, for that you must maintain saving the state of the accumulator and aggregating the outcomes each step of the best way. The scan() perform is arguably higher suited to our functions:
perform scan(arr, reducer, initialValue) {
let accumulator = initialValue;
const outcome = [];
for (const currValue of arr) {
const curr = reducer(accumulator, currValue);
accumulator = curr;
outcome.push(curr); }
return outcome;
}
It shops the accumulator values at every step by design, which is precisely what we want on this case. With the assistance of **scan() **it’s now simple to course of all of the Supply map parts:
scan(gadgets, sourceMapReducer, [0, 0, 0, ‘-‘, -1]);
The sourceMapReducer() perform splits every Supply map aspect into separate fields. On the identical time, we save the report quantity within the Supply map, as will probably be wanted later. If a worth is lacking, the respective one from the accumulator is taken.
perform sourceMapReducer(acc, curr) {
const elements = curr.break up(‘:’);
const fullParts = [];
for (let i = 0; i < 4; i++) {
const fullPart = elements[i] ? elements[i] : acc[i];
fullParts.push(fullPart);
}
const newAcc = [
parseInt(fullParts[0]),
parseInt(fullParts[1]),
parseInt(fullParts[2]),
fullParts[3],
acc[4] + 1
];
return newAcc;
}
2.2. Contract bytecode
In json, bytecode is represented as an enormous quantity in hexadecimal notation.
The EVM (Ethereum Digital Machine) bytecode format is kind of easy. All instructions match into one byte, with solely exception being the directions which load constants onto the stack. The dimensions of the fixed can fluctuate from 1 byte to 32, and it’s encoded within the first byte of the instruction. The remaining bytes include a continuing.
Bytecode parsing could be narrowed all the way down to a sequential byte studying of a hexadecimal quantity. If the byte learn is a continuing loading instruction, we decide the variety of bytes and instantly learn the entire fixed.
perform parseBytesToInstructions(bytes) {
const directions = [];
let i = 0;
whereas (i < bytes.size) {
const byte = bytes[i];
let instruction = [];
if (firstPushInstructionCode <= byte && byte <= lastPushInstructionCode) {
const pushDataLength = byte – firstPushInstructionCode + 1;
const pushDataStart = i + 1;
const pushData = bytes.slice(pushDataStart, pushDataStart + pushDataLength);
instruction = [byte, …pushData];
i += pushDataLength + 1;
} else {
instruction = [byte];
i++;
}
directions.push(instruction);
}
return directions;
}
2.3. Aggregating the information collected
Now we have now all the knowledge required to kind the primary illustration: an array with disassembled contract directions, and one other array with information ample to find out the corresponding block of supply code for every instruction. Due to this fact, to create the “instruction — code fragment” illustration, we will merely undergo these two arrays concurrently “gluing collectively” data from them elementwise.
3. Mapping code snippets with directions
It might appear that by establishing the “instruction — supply code” illustration within the earlier part, we killed two birds with one stone and there’s nothing left to do to kind the “supply code — instruction” illustration. This may be true, certainly, if a single instruction within the supply map would match precisely one line of supply code. Sadly, that’s not the case.
One instruction could be assigned to a number of strains within the supply code file without delay. Furthermore, directions can consult with the entire technique physique and even to the entire contract! Very often 100 consecutive directions are tied to your complete code of the one contract. The next bunch of directions, fairly as large because the earlier one, is tied to some technique of the contract, and the subsequent bunch — to the entire contract once more. How helpful such a stream with a great deal of duplicate strains of supply code could be could be very a lot in query.
The higher answer is to construct a tree construction from the blocks of code, integrating the smaller ones (contract strategies) into massive blocks (the contract itself). Then to every node of this tree we will tie all of the corresponding directions. The info construction like that’s approach simpler to research.
3.1. Constructing a tree
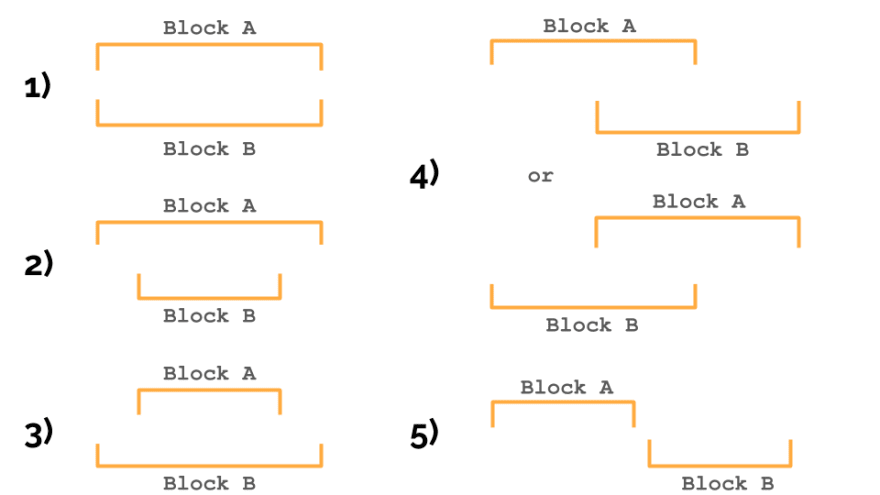
We are going to construct a construction step-by-step, iterating by way of all contract directions and including them one after the other to the tree. Two blocks of supply code could be in one of many following relationships:
- blocks are equal
- the primary block accommodates the second
- the primary block is included within the second
- blocks intersect
- blocks don’t intersect
Now, once we khow to outline the connection between the 2 blocks, we will construct our tree with the addNode() perform. It finds the fitting place for a brand new block within the tree, recursively scanning it ranging from the basis. Let’s take a look at a simplified model this perform:
perform addNode(currentNode, block) {
const relation = classifyBlock(currentNode.block, block);
outer:
swap (relation) {
case equalBlock:
// do nothing
break;
case childBlock:
const [children, nonChildren] = splitChildren(currentNode.youngsters, block);
if (youngsters) {
currentNode.youngsters = [
…nonChildren,
createNode(block, children),
];
} else {
for (const childNode of currentNode.youngsters) {
const childRelation = classifyBlock(childNode.block, block);
swap (childRelation) {
case childBlock:
addNode(childNode, block);
break outer;
case neighborhoodBlock:
proceed;
default:
throw new Error(‘Unknown relation’);
}
}
currentNode.youngsters.add(createNode(block));
}
break;
default:
throw new Error(‘Unknown relation’);
}
}
First, we outline the relation of the added block to the block of the present node within the tree (line 2). If the blocks are equal, it implies that the block already exists within the tree and no additional motion is required (strains 6-8).
The place it will get fascinating is when the block into consideration is a toddler of the block of the present node (strains 7-31). Right here we have to think about three potential situations: The brand new block is the mother or father for some baby blocks of the present node (strains 12-15).

A brand new block is a toddler of one of many baby blocks of the present node (strains 17-28)
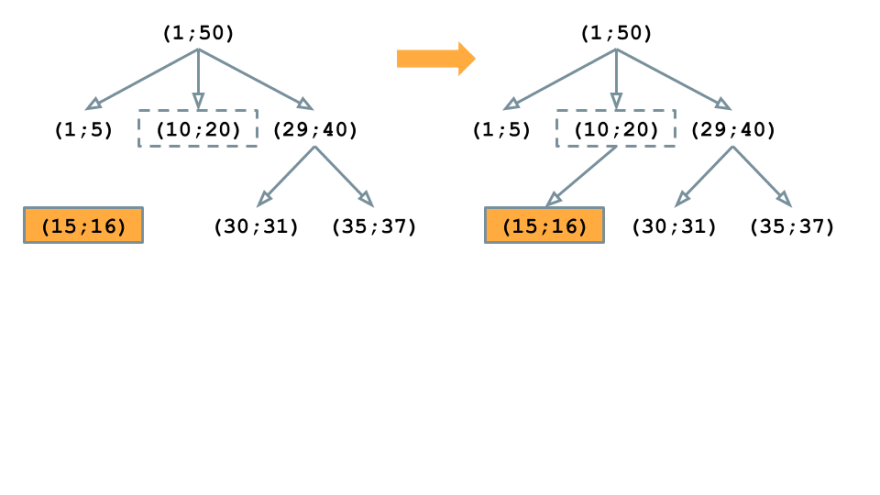
The brand new block is a direct baby of the present node (line 29)

Within the first and third case we rebuild the instant youngsters of the present node accordingly. Nonetheless, within the second situation we have to recursively go one degree down.
Now let’s think about an instance. Suppose the physique of our contract consists of 6 directions n1-n6, which correspond to the strains of the supply code as follows:
n1: (1;15)
n2: (1;15)
n3: (1;7)
n4: (8;15)
n5: (3;3)
n6: (4;4)
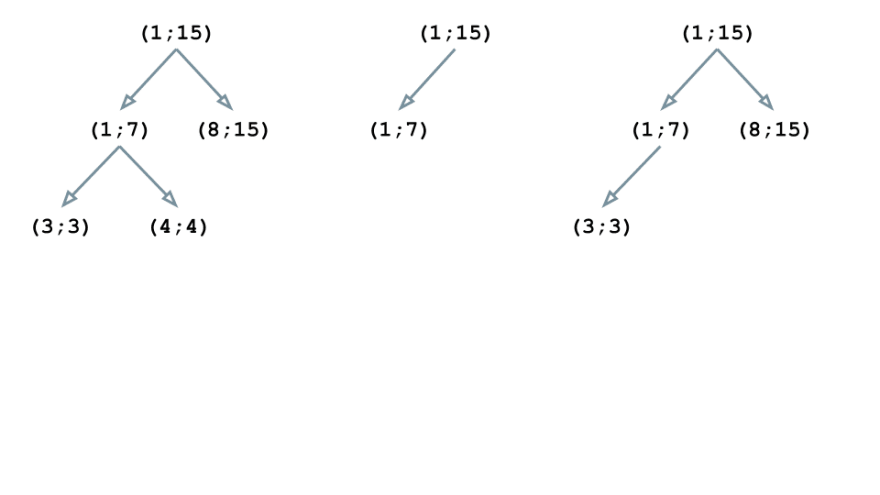
The primary instruction is n1, and the corresponding block (1; 15) turns into the basis of our tree construction:

The n2 instruction has the identical block because the earlier one, so the tree doesn’t change:

The block (1; 7) of the instruction n3 is nested in (1; 15), so we rebuild the construction:

The block (8; 15) can be embedded within the root aspect of the tree (1; 15). Nonetheless, this block is neither a mother or father for (1; 7), nor a toddler, so the tree will get this way:
The block (3; 3) is nested in (1; 15) and (1; 7), thus changing into a toddler of (1; 7):
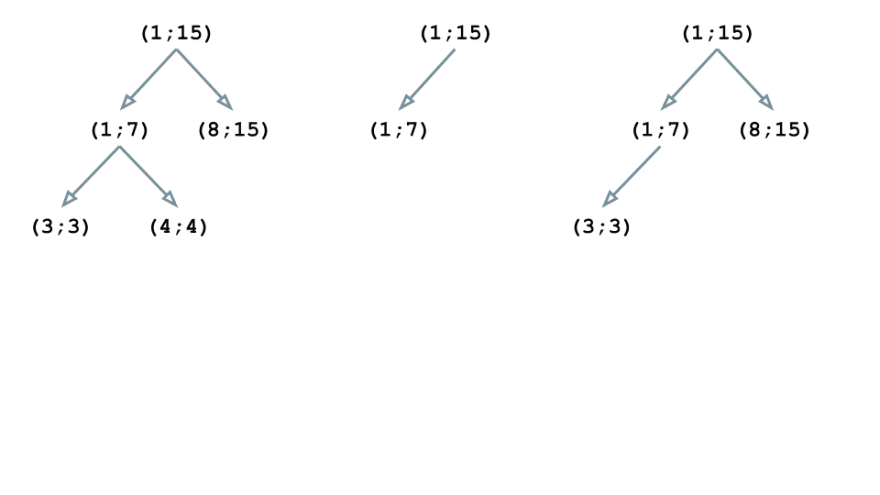
Equally, (4; 4) is embedded in (1; 15) and (1; 7) however it doesn’t intersect with (3; 3); due to this fact, it turns into the second baby node of (1; 7)
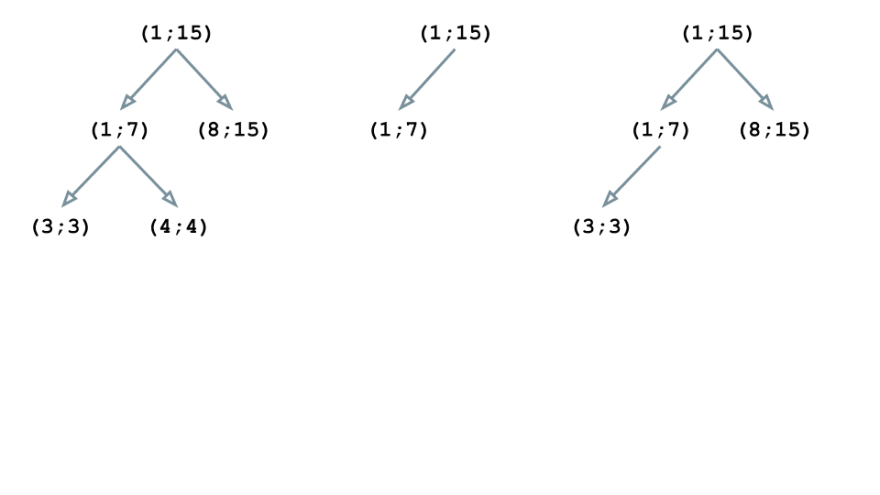
Thus, all of the blocks are in place and the we have now our tree construction constructed. Now we will improve it with helpful data such because the textual content of the supply code for the blocks, in addition to some assembler directions.
4. Conclusion
When compiling the contracts, Truffle generates very helpful information which will help you to understand how your code really behaves and what precisely it does within the blockchain. That is additionally a handy method to analyze bottlenecks in your code. Nonetheless, this information isn’t precisely intelligible from the primary sight, and right this moment you’ve realized learn how to perceive the format of it and determine a method to current it in a easy and handy kind for additional evaluation.
Thanks for bearing with us by way of this lengthy and technical publish. We hope you loved it and located it helpful. Keep tuned for extra insights from us, we will’t wait to share with you extra of our hands-on Blockchain expertise and enjoyable tales!
Code laborious. Construct large. Decentralize.
Yours,
EQ LAB Group